2025年5月21日、Googleは開発者向け年次イベント「Google I/O 2025」において、生成AIを中心とした一連の新技術群を発表しました。
今回の発表は、従来の“研究成果の共有”や“技術の紹介”という枠を越え、実務・事業への実装を前提とした具体的な戦略とプロダクト群の提示がなされた点で、大きな転換点を示すものとなりました。
とりわけ、業務支援や意思決定補助を目的としたAIモデルの進化、自律的な処理を担うAIエージェント、そしてクリエイティブ業務やコミュニケーション領域にまで広がるAIの応用技術は、単なる作業支援ではなく「業務構造の再定義」を視野に入れたものであるという印象を残しました。
本記事では、Google I/O 2025で発表された生成AI関連の主な技術群を、4つの観点に沿って整理していきます。
1つ目は、GeminiのAIモデルの進化です。より高度な文脈理解や推論機能を備えた新モデルが、業務にどのような影響を及ぼすのか?
2つ目は、AIエージェントの実用化で、AIがタスクを自律的に実行する機能というのはどの程度の実用性があるのか?
3つ目は、クリエイティブ領域への応用で、映像・画像・音楽といったクリエイティブな制作活動にどのような影響を及ぼすのか?
4つ目は、次世代コミュニケーションの展開で、翻訳や3D対話、XRといった技術が、情報の伝達や共有のあり方をどのように変えていくのか?
それでは、Google I/O 2025で発表された内容を1つずつ解説していきます!

1.Gemini 2.5:生成AIは“使える段階”から“組み込まれる段階”へ
2025年のGoogle I/Oにおける中核的発表の1つが、Gemini 2.5シリーズの正式公開でした。
このモデルは、自然言語処理やプログラム生成といった従来の機能をベースとしつつも、実務課題に即した構造的思考能力と、長期的な文脈保持と推論能力を兼ね備えた、業務適用前提の生成AIとして設計されています。
Gemini 2.5 Pro:意思決定補助エンジンとしての進化
中でも「Gemini 2.5 Pro」は、戦略設計や分析、コード自動化、長文処理といった高度な業務領域に対応するための上位モデルです。従来のLLMとは一線を画す新機能が「DeepThinkモード」です。
このモードでは、1つの課題に対して複数の解釈やアプローチを同時並行で検討し、それぞれの可能性について評価・提示することが可能となっています。
例えば、事業戦略における市場拡張の施策について質問した際、「コスト優先策」「差別化優先策」「チャネル多角化策」など、複数の論点を自動的に立て、それぞれのリスク、実行工数、収益モデルまでを俯瞰するようなアウトプットが得られます。これは、AIが単に答える存在から、「検討のフレームワークを提示する存在」へと移行したことを意味します。
また、最大100万トークンの文脈保持能力は、法務文書や過去の契約履歴、プロダクトマニュアル、過去案件に関する議事録や設計資料などを統合的に把握し、全体の整合性をとりながら分析・応答することを可能にします。部門横断的な業務設計やマルチステークホルダーを想定した提案業務において、前提の理解を省略せずに話を進められるAIとしての価値が際立ちます。
実際、Googleが公表した「WebDev Arena」でのベンチマークにおいて、Gemini 2.5 Proは首位の性能を記録しました。この指標は、単に正確なコードを書く能力だけではなく、UI設計の一貫性、データ処理の信頼性、アクセシビリティ、そしてセキュリティ要件への対応まで含めた総合評価であり、企業システムの現場における“実務水準”をクリアしていることの証左です。
Gemini 2.5 Proは現在、Google Workspace、Google Cloud、そしてGeminiアプリケーション群に段階的に統合されており、社内ツールや外部顧客向けアプリケーションにおける直接的な業務統合が可能となりつつあります。
Gemini 2.5 Flash:効率性と速度の両立
一方、軽量モデルである「Gemini 2.5 Flash」は、コストと処理効率に重点を置いた設計が施されており、会話AI、問い合わせ自動応答、簡易的な要約・翻訳、軽量推論処理など日常業務を下支えするAI基盤として位置づけられています。
特筆すべきは、従来のモデルと比較してトークン消費量が約20〜30%削減されている点です。
特にAPIベースでの大量生成・大量問い合わせにおいて、システム全体の運用コストを大きく抑制することにつながります。カスタマーサポートチャットや社内ヘルプデスクなど、繰り返し頻出する問いに対して、高速かつ安定した応答を返す用途で非常に有効です。
また、FlashはProと同様にマルチモーダル対応を備えており、画像・音声・文書といった複合入力に対応。ユーザーから送られたスクリーンショット、音声メモ、図表を解析し、内容を構造化した上で応答するといった、現場密着型の利用シナリオが展開可能です。
2.AIエージェントの実装段階──業務が“動く”AIとの協働を前提とする時代へ
Google I/O 2025では、「AIが情報を生成する」段階から、「AIが自律的に行動する」段階への移行が明確に提示されました。
その中核を担うのが、Project Mariner、Project Astra、そしてGeminiアプリに統合されたAgent Modeです。これらは単に支援的なツールではなく、複数のステップを理解し、意思を持ったかのように業務を代行・実行するエージェントとして設計されています。
Project Mariner:ブラウザを自律的に操作するAIオペレーター
Project Marinerは、Chromeブラウザと直接統合されたAIエージェントであり、人間が行う一連のWeb上の操作をそのままAIが実行できるという特徴を持ちます。たとえば、ユーザーがネットバンキングにアクセスし、ログインして履歴を確認し、CSVでエクスポートするといった一連の操作──これをMarinerは「タスク」として認識し、画面構造を理解しながら自律的に処理します。
この技術のポイントは、「手順の自動化」ではなく「目的の達成」です。単なるRPA(ロボティック・プロセス・オートメーション)との違いは、画面構造が変化しても目的が変わらない限り、対応を継続できる点にあります。
例えば、WebページのUIが変更された場合、従来のRPAでは修正が必要ですが、Marinerはページの意味構造を再解析して対応を継続します。
想定される利用シーンとしては、定期的なデータ収集、自社サイトの更新・監視、競合サイトの価格変動監視、調査業務の代替などが挙げられます。バックオフィスの反復作業の自動化だけでなく、顧客対応業務や営業支援ツールとしての運用も十分視野に入ります。
Project Astra:カメラと音声からリアルタイムで世界を理解するAI
Astraは、マルチモーダルAIとして設計された実用的な認知エージェントです。
スマートフォンのカメラやマイクから入力される現実世界の映像・音声をリアルタイムで解析し、理解・対話・指示処理を行う機能を持ちます。
すでにGoogleは、AndroidおよびiOS向けのAstra機能の実装を開始しており、ユーザーがカメラを向けた物体や文書、画面上のアイコンなどを即座に認識し、「これはどのように使いますか?」「どの設定が最適ですか?」といった対話が行える段階に入っています。
このような特性から、現場対応型の業務──例えば設備保守、医療サポート、教育、物流、店頭業務などにおけるナビゲーションや即時の補助エージェントとしての応用が期待されます。将来的には、AstraはXRグラスとの統合が計画されており、「視界上に重ねる情報・提案・指示をリアルタイムに提供する“実空間アシスタント”」としての発展が見込まれています。
Agent Mode(Geminiアプリ):複雑なマルチタスクを個人最適化で実行
一方、Geminiアプリに搭載されたAgent Modeは、より個人向けの業務支援に特化しています。
複数のサイト・システムにまたがる情報取得、比較、要約、タスクの分解・実行までをAIが自律的に進行します。重要な機能の一つが「パーソナルコンテキストの学習と活用」です。
ユーザーが過去に検索した情報、カレンダーに登録している予定、過去の議事録やドキュメント履歴などをもとに、個人の業務文脈を継続的に保持し、最適な情報収集や提案が可能になります。
この仕組みは、単なる会話型AIを超えて、「業務パートナー」としてのAIの基礎を構築するものであり、
例えば「来週の予算会議用に、最新の売上推移と業界比較をまとめてほしい」という抽象度の高いリクエストに対しても、関連データの収集・要約・ドラフト作成を一括で対応することが可能です。
3.生成AIクリエイティブ──映像・画像・音楽制作の業務統合が現実に近づく
従来、映像・画像・音楽といったクリエイティブ領域は、生成AIが最後まで入り込みづらい分野とされてきました。
しかし、Googleが今回発表したVeo 3、Imagen 4、Flow、Lyria 2といったツール群は、この前提を確実に塗り替えつつあります。いずれも企業が自社内で「制作・修正・試作」を反復可能にするための実用段階に入り、映像制作やブランド表現といった分野での“AIの内製化”を加速させています。
Veo 3:映像を構成するAI、“演出”まで担う次世代モデル
Veo 3は、生成AIによる動画生成ツールの最新版であり、テキスト入力からストーリー性を持った高解像度動画を出力できる点が特長です。
今回のアップデートでは、以下のような能力が追加されました。
- ネイティブ音声の生成:人物の口の動きと音声が自然に一致する高度なリップシンク処理。
- 物理シミュレーションの精度向上:衣服の揺れや光の反射といった要素も自然に再現。
- 会話、環境音、背景効果の自動生成:ワンプロンプトで“シーンとして成立する映像”が成立。
これにより、たとえば企業が新製品のイメージ動画を制作する際、従来の外注や実写撮影に頼らず、社内の広報・企画部門がプロンプト設計だけで試作と検証を繰り返すことが可能になります。映像品質は4Kまで対応し、広告、研修、リクルートムービーなど多様な業務用途での展開が視野に入ります。
Imagen 4:静止画生成の解像度と再現力が一線を画す
Imagen 4は、Googleの画像生成モデルであり、今回のアップデートではテクスチャ表現の繊細さと文字・ラベル生成の正確性が大幅に向上しました。
これにより、製品モックアップや広告ビジュアル、提案資料のイメージなど、ビジネスコミュニケーションに必要な視覚要素を正確に描き出すことが可能です。
- 2K解像度対応:印刷・大型モニター用素材としても十分な精度。
- 任意アスペクト比対応:SNS、バナー、プレゼン用など用途に応じたフォーマットに即時対応。
- 文字入りビジュアルの高精度化:ブランドロゴや説明文なども自然に統合。
特にプレゼン資料やWeb広告、商品ページの画像素材として、従来のストックフォトやデザイン依頼に代わる選択肢として注目されています。
Flow:制作プロセス全体を統合する“映像ワークスペース”
Flowは、Veo、Imagen、Geminiを統合した映像制作プラットフォームです。これまで映像制作に必要だった複数ツール間の移動やファイル変換、アセット管理といった煩雑な工程をワンシステムで完結できる構造が用意されています。
- シナリオからシーン分割、キャスティングまでを自動化。
- シーン構造、カメラ視点、表情演出までの細かな制御が可能。
- 再利用性を考慮したテンプレート生成・素材管理。
これにより、企業のインハウス制作体制でも、試作・修正・適応までのサイクルを高速化することが可能になります。
例えば、営業部門が商談先ごとに訴求ポイントを変更した映像を即座に出力し、個別提案として活用するといった使い方も現実味を帯びてきました。
Lyria 2:AI音楽制作が“プロフェッショナル仕様”に対応
音楽生成AI「Lyria 2」は、今回のアップデートでプロユースに耐えうる精緻な音楽制御機能が追加されました。
- BPM、調(キー)、ジャンル指定など細かなパラメータ設定に対応
- 複数トラックの構成やテンションの変化、間奏・ブレイクなどの構成制御
- Googleが提供するSynthIDによる著作権保護機能(透かし埋め込み)を標準搭載
Lyria 2は、音楽制作者向けの“Sandbox”として展開されており、企業が使用する場合にはCM・プロモーション動画・店舗BGMなどに活用可能です。著作権処理済みの生成楽曲を短納期で作成できることは、特に法務要件の厳しい企業にとって大きな利点です
Googleが今回提示した「次世代コミュニケーション」関連技術群は、従来の生成AIとは異なる角度から、人と人の関係性、空間、理解の“あり方”を再構成する技術基盤となっています。
物理的距離や言語の壁を越えて、「会話」や「存在感」そのものを高精度に再現・拡張する仕組みが提示されました。
4.Google Beam:3D再構成による“対面の再現”
Beamは、Googleがこれまで開発してきたProject Starlineの進化版であり、複数のカメラとリアルタイムAI処理によって、対話相手を3D映像として再構成・表示するシステムです。
今回のI/Oで発表された仕様では、6カメラアレイとミリ単位の頭部追跡、60fpsでの映像再構成が可能となり、リモート会議でも相手の表情や視線、体の動きまでが実際に“そこにいる”ような感覚で伝わるようになりました。
HPとの提携により、2025年中には初期製品の市場投入が予定されており、特にグローバルチーム間の経営会議、重要顧客との商談、医療・教育・設計など“感覚的な情報共有”が重要な分野での活用が期待されています。
この技術は、映像通話という枠組みを超え、**「実在感を持つ対面の再構築」**として捉える必要があります。
今後、拠点間のコミュニケーション環境そのものの設計を見直す契機となる可能性があります。
Google Meetのリアルタイム翻訳:多言語対応の“ニュアンス保持型”翻訳
Google Meetでは、英語⇔スペイン語のリアルタイム翻訳が開始され、今後数週間以内に他言語(ドイツ語、イタリア語、ポルトガル語など)への対応が拡大される予定です。
今回の特徴的な進化は、言葉の意味だけでなく、話し方・抑揚・感情のニュアンスまでを保持した翻訳を可能にした点にあります。これにより、ビジネス交渉やコーチング、チームの感情的な共有など、従来の機械翻訳が不得意とした「空気感の伝達」も可能となります。
企業にとっては、これが通訳コストの削減や多国籍チーム内の意思疎通の質的向上に直結するのみならず、“言語前提の壁”がなくなる世界観の入り口とも捉えることができます。
AlphaEvolve:AIがアルゴリズムそのものを進化させる時代
AlphaEvolveは、Google DeepMindとGeminiモデルによって構築された、進化的アルゴリズム探索エージェントです。
このモデルは、既存の設計原理や人間が定義した最適化ルールに従うのではなく、「結果から逆算して最適な手法を自ら発見・生成する」機能を持っています。
例えば、Google内部のデータセンターにおいては、AlphaEvolveの導入により電力効率が0.7%向上しました。これは一見すると小さな数値ですが、全世界のGoogleインフラ規模では数千万ドル単位の省エネ効果をもたらす結果となっています。
さらに、FlashAttentionなどの高速推論技術に対しても独自改良を加え、最大32%の処理時間短縮を達成。今後、業界横断的に「設計ルールをAIに委ねる」という構造改革のきっかけになる可能性があります。
企業においては、R&D部門、プロダクト設計、シミュレーション領域など、高い専門性と反復性が求められる業務への適用が現実的となってきています。
Android XR:物理空間に知性を拡張する“新たなプラットフォーム”
最後に、Googleは次世代XR(Extended Reality)プラットフォームをAndroidベースで統合展開する方針を打ち出しました。
Samsungと共同開発中の**「Project Moohan」ヘッドセットに加え、Gentle MonsterやWarby Parkerと連携したスタイリッシュなXRグラス**も同時に発表されており、日常利用を意識した“顔の前のAI”の展開が始まります。
これらのデバイスにはGeminiモデルが直接統合される予定であり、音声・視線・ジェスチャーといった入力をもとに、ユーザーの意思や行動を理解し、現実空間とデジタルインターフェースを接続する“知的補助機能”としての役割が期待されています。
具体的なビジネス活用としては、フィールドワーク、遠隔作業支援、スマートファクトリー、メディカルナビゲーションなどが挙げられ、将来的には、“視界上で情報が常に展開される働き方”がごく自然な選択肢になると考えられます。
新しく追加された料金プラン
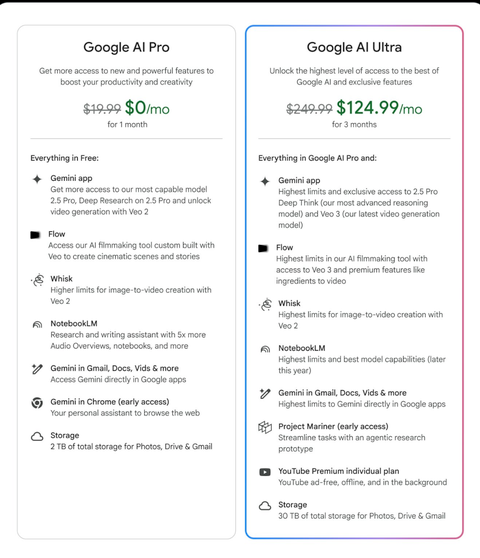
【Google AI Pro】
料金:$19.99 → $0/月(初月無料)
無料プランに含まれる全機能に加えて、以下の項目を利用可能。
- Geminiアプリ:最も高性能なモデル「2.5 Pro」、Deep Research on 2.5 Pro、Veo 2による動画生成機能にアクセス可能
- Flow:Veoと連携して映画のようなシーンやストーリーを作成するためにカスタム構築されたAI映像制作ツール
- Whisk:Veo 2を用いた画像から動画への変換において、より高い使用上限
- NotebookLM:音声オーバービュー、ノートブックなどにおいて、5倍の上限で使えるリサーチ&ライティングアシスタント
- Gmail、Docs、VidsなどのGoogleアプリ内でGeminiが利用可能
- ChromeでGeminiを利用(アーリーアクセス):Webブラウジングのパーソナルアシスタントとして使用
ストレージ:Google フォト・ドライブ・Gmail用に合計2TBのストレージを提供
【Google AI Ultra】
料金:$249.99 → $124.99/3ヶ月間
Google AI Proの全機能に加えて、以下の項目を利用可能。
- Geminiアプリ:最上位の使用上限と、2.5 Pro Deep Think(最も高度な推論モデル)および最新の動画生成モデル「Veo 3」への排他的アクセス
- Flow:Veo 3へのアクセスと、「レシピ→動画」などのプレミアム機能付き、最高レベルの映像生成上限
- Whisk:Veo 2による画像→動画変換で最上位の使用制限
- NotebookLM:今年後半に導入予定の最高レベルの使用制限とモデル機能
- Gmail、Docs、VidsなどGoogleアプリ内でのGemini利用において最高の上限
- Project Mariner(アーリーアクセス):作業を効率化するAIエージェント型リサーチプロトタイプ
- YouTube Premium 個人プラン:広告なし、オフライン再生、バックグラウンド再生対応
- ストレージ:Google フォト・ドライブ・Gmail用に合計30TBのストレージを提供

まとめ
Google I/O 2025で示された生成AIの進化は、単なる技術更新にとどまらず、組織運営や事業設計の根本的な前提を再定義する内容となりました。
中心に位置づけられたGemini 2.5シリーズ──特にProモデルの登場は、AIが“思考と構造の補助者”として機能し始めていることを象徴しています。DeepThinkモードによる複数仮説の同時検討、100万トークン対応による長文処理力、WebDev Arenaでの実績といった要素は、これまで人間が担ってきた分析・設計・評価といった高度なプロセスに、AIが実用水準で介在できる段階にあることを明確にしました。
同時に、Flashモデルは高頻度・高ボリュームでの利用に適した構成となっており、社内のドキュメント要約や問い合わせ対応、日常業務の自動処理といったタスクにおいて、コスト効率と応答速度を両立できるモデルとして位置づけられます。これにより、企業はAI導入に際して「高度思考支援」と「日常実務支援」という2つの軸でツールを選び、組み込むことが可能となっています。
また、AIが“情報を生成する存在”から、“目的を理解し動作を遂行する存在”へと変化し始めている点は、Project MarinerやAgent Mode、Astraによって如実に示されました。これらのエージェント型AIは、Web画面の理解、ユーザーの目的の推定、マルチステップタスクの自律的な完了といった機能を有し、これまでRPAや人の手によって分割されていたプロセスを一貫して担える能力を備えています。業務の中でAIが“行動者”として組み込まれる──この構造は、単なる補助ツールの導入ではなく、業務設計の段階からAIの存在を前提とする再構築を意味します。
さらに、VeoやImagen、Flow、Lyriaといったクリエイティブ領域の生成AIツールは、企業内での映像・画像・音楽制作の大幅な効率化、さらには試作・検証サイクルの高速化に直結するポテンシャルを提示しました。プロンプト一つで高品質なPR動画や広告ビジュアル、音楽素材を内製化できるこれらのツールは、従来の制作ワークフローを抜本的に変えるものであり、社内のクリエイティブ業務において「外注ありき」の発想を根底から再考させるものです。
そして、Google Beamやリアルタイム翻訳、XRプラットフォームといった次世代コミュニケーション技術は、働き方や国境を越えたチーム構成を支える“空間と関係の再構築”を視野に入れています。これまでの会議システムや通訳サポートを超えて、存在感や文脈、文化的ニュアンスまで含めたコミュニケーションの質的転換が始まろうとしています。
これらすべての発表を総合すると、Google I/O 2025は「AI技術の未来を語る場」ではなく、「業務設計と組織構造を現時点で再構築するための材料が出揃った場」であったと捉えるのが適切です。各企業は今、生成AIを“検討すべき先進技術”として捉える段階から、既存の業務フロー・人員配置・アウトプットの形式そのものを再設計する前提技術として受け止めるべき局面に移行しています。
AIを“使うかどうか”ではなく、“どのように使い分け、どの業務に統合するか”が改めて問われています。
これからの経営に求められるのは、最新機能の理解以上に、変化が日常となる環境において、持続可能なAI統合戦略を描き続ける姿勢なのではないでしょうか。
参考情報
https://blog.google/intl/ja-jp/google-io-2025/
https://developers.googleblog.com/ja/get-ready-for-google-io-2025/
https://www.youtube.com/watch?v=o8NiE3XMPrM